This is Bob, the snail.

Bob just hacked your company’s authentication database, containing your customer’s secrets. Depending on how well you’ve secured those secrets, Bob either becomes a rich and happy snail, or he ends up getting nothing.
So let’s see what happens to Bob, based on how you stored your company’s secrets.
Level 0 – Plain Text
At level 0, it’s amateur hour. Your secrets are all stored in plain-text.
Your team is composed of literal monkeys who accidentally created a piece of software by mashing random buttons until they got a program that compiled.

Because you’ve stored all of the passwords in plain-text, Bob now has instant-access to all of your customer’s information. Not only that, since most people use the same password on several websites, he’s got access to those accounts as well.
Bob now gets to relax on the forest floor, while money showers down on him from all of the accounts he’s hacked.
Level 1 – Hashing
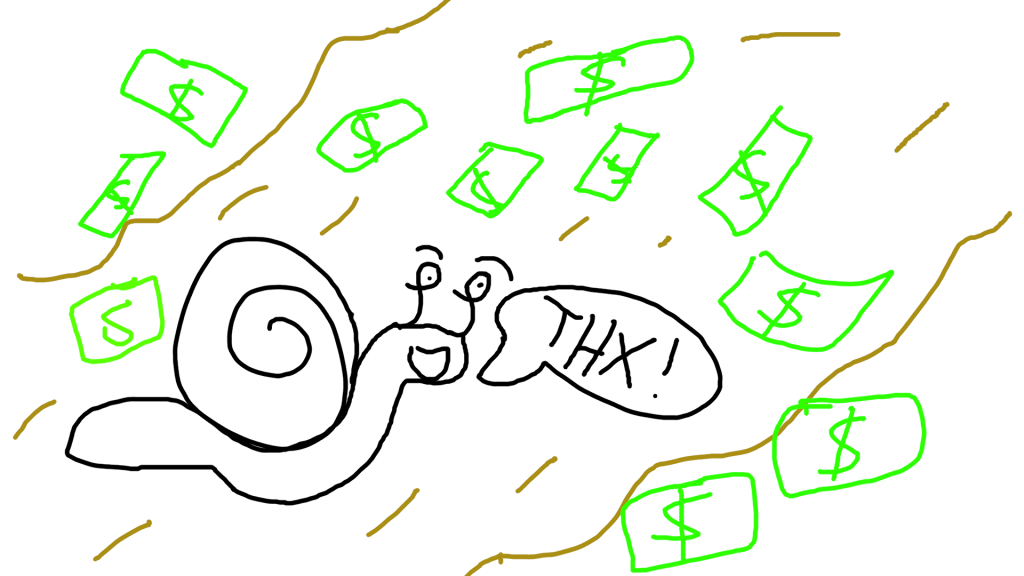
One step up from plain-text is basic hashing with SHA256. When you hash a string, you get another string as output. This output is always the same length, regardless of its input length.
Additionally, the hash function is irreversible, and doesn’t give you any useful indication about the input. In the example below, the SHA256 hash for “foo” and “fooo” are completely different, even though they are only one letter apart.

While hashes can’t be reversed, they can be cracked. All Bob has to do is bring out his trusty tool, the rainbow table.

You see, hashes have a problem, which is that they always produce the same output no matter what.
In other words, when I use SHA256 to hash “foo”, I always get “2c26b46b68ffc68ff99b453c1d30413413422d706483bfa0f98a5e886266e7ae” no matter what.
What Bob has done, is used something called a “rainbow table”, which is a table that contains input keys, and the hashed outputs for those keys (typically as chains of hashes).
Theoretically, if Bob had lots of storage space, Bob could generate all possible passwords up to 8 characters in length, hash every single of those passwords, and store them. Once Bob has assembled his rainbow table, Bob will be able to automatically crack any password hashed with SHA256 in the blink of an eye if it’s 8 characters or less.
Why? Because Bob has already pre-computed all the possible hashes for all 8 (or less) character passwords.
Realistically, Bob is bottlenecked by memory and computation times when it comes to how long his rainbow table can be. Let’s say passwords can contain alphanumerical characters (35 possibilities) and symbols that are located on a normal keyboard, like +, -, ~, \, etc. This gives us an additional 21 possibilities.
In reality, there are way more possible characters, but let’s say that there were 56 in theory as a lower bound. If Bob wants to generate all 5 character possibilities, Bob needs to generate 550,731,776 inputs, and hash all them.
Here’s a chart that shows how absurd the rate of growth is for rainbow tables (assuming 56 possibilities per character):
| # characters | # of generated inputs |
| 1 | 56 |
| 3 | 175,616 |
| 5 | 550,731,776 |
| 8 | 96,717,311,574,016 |
| 10 | 303,305,489,096,114,176 (303 quadrillion) |
| 16 | 9,354,238,358,105,289,311,446,368,256 (9 octillion) |
As you can see, rainbow tables really can’t extend very far. Eight characters is still feasible, but after that, it gets inordinately expensive. A 16-character rainbow table would be incredibly difficult to store, and would take an eternity to generate. Note that 56 characters is an incredibly low bound, since there are many other characters that can be used as well. You should expect it to be even more expensive, in practice, to generate a full rainbow table for all 1-8 character passwords.
Level 2 – Salt And Hash
Clearly, the problem with our previous approach was that we were hashing passwords, but these hashed passwords could be cracked by a rainbow table.
So how do we prevent rainbow tables from being used against us?
By using salts! A salt is just a simple string that, in many cases, is just appended to your password before it’s hashed. These salts are generally randomly generated and quite long (16+ characters), which means that our user’s password (8-16 characters) plus the salt (16 characters) should be at least 24 characters long (also note that every password should have a different salt).
This makes our unhashed password at minimum 24 characters, so this password can’t exist in a rainbow table because no one has the capability to generate all possible passwords up to 24 characters long.
We then hash this password, and store both the hashed + salted password, as well as the salt itself, in our database.
But what about our salt? It’s stored in plain-text!
The salt actually has to be stored in plain-text, because the way we verify a salted hash is that we take the user’s inputted password, append the salt, then hash it. If it matches what’s in our database, then it’s the correct password.
So how does all of this effect Bob? Well for starters, it makes the rainbow table incredibly useless. Although Bob has our salt, Bob can’t use his rainbow table against us, unless he re-generates an entirely new one, where each input has the salt appended to it.

For example, suppose our password was “foo”, and the salt was “saltyfish”. Without the salt, Bob would instantly be able to figure out the hash for “foo”. But with the salt, Bob now has to take all of his inputs, append “saltyfish” to them, and only then, will he find that “foosaltyfish” gives a hash match.
Once Bob finds the correct match, he removes the salt (“saltyfish”), leaving him with “foo”. And that’s our password! So Bob can still manage to hack our account.
But that was a really expensive operation. You don’t want to have to re-generate an entire rainbow table, because they’re often petabytes or larger in size. And the whole process of doing that only allowed you to hack one user! If Bob has to go through 300 million users, he would have to regenerate his rainbow table 300 million times, because every password has a different salt!
With your secrets safely salted, Bob has no choice but to find other unwitting victims to hack. Preferably, ones who haven’t salted and hashed their passwords.