Most people would tell you that hard work and perseverance are important if you want to be successful, but sometimes it pays to be lazy.
When it comes to programming, however, being lazy has plenty of benefits, and lazy evaluation is just one of those examples. Lazy evaluation is the idea of delaying the evaluation of an expression until the very moment in which you need it.
Lazy evaluation is most commonly used in functional programming languages, and the one of highest notoriety is Haskell, which is a completely lazy language by default (unless you tell it not to be)
How’s Lazy Evaluation Work?
Imagine that you’re a UPS (United Postal Service) employee and your job is to deliver some packages to your customer’s doorsteps.
Unfortunately, you are notoriously also the worst employee in your department.

Unlike a good employee, you don’t respect “Fragile” labels. In fact, you’re not even aware that the package is fragile at all. That’s why in the interest of time, you hurl every package you have, directly onto the hard, unforgiving concrete of your customers’s yards.
Do your packages make it in one piece? Who knows! You never look inside the box. For all we know, the box could be a bunch of stuffed animals, or it could be a very expensive $2,000 laptop that’s as fragile as a piece of glass.
As far as you are concerned, you have a box, and you transport it to someone else. This “box” is the expression, and evaluating the expression would be like opening the box to see its contents. While there is also metadata about the box, like whether it’s fragile or not, you have no clue whether it’s fragile or not until you read the information off the box.
Simply put, the essence of lazy evaluation is that you don’t know what’s inside something until you look at it. Initially, this sounds pretty simple and obvious. If you don’t look inside the box, how can you know what’s in it?
And that’s where it takes a loop. All of these boxes act like the box in Schrödinger’s cat experiment.

When it comes to lazy evaluation, you have no clue what’s in the box, but also there isn’t actually anything tangible in the box either. In a lazy evaluation model, to get a result out of the box, you would need to open it, and the very act of opening it causes the value inside to come into existence. Prior to opening the box, the box is essentially empty (an unevaluated expression, to be precise). It weighs nothing, makes no noise, and otherwise acts exactly like a normal box.
This can give us some pretty neat results. For example, suppose you have an expression like 1 divided by 0. This is the expression, which in our analogy, is the box. In a language like Python or Java, you would immediately crash with a divide by zero error.
But in Haskell, you can have an expression like “div 1 0”, and as long as you don’t evaluate it, nothing happens! You don’t get an error, because until you evaluate “div 1 0”, it simply exists as an expression with no value. Once you evaluate it (open the box, in this case), Haskell finds that the value is erroneous, and an error pops out.

Going a step further, what if you had a list that contained all of the numbers from 0 to infinity? (denoted as [0, infinity])
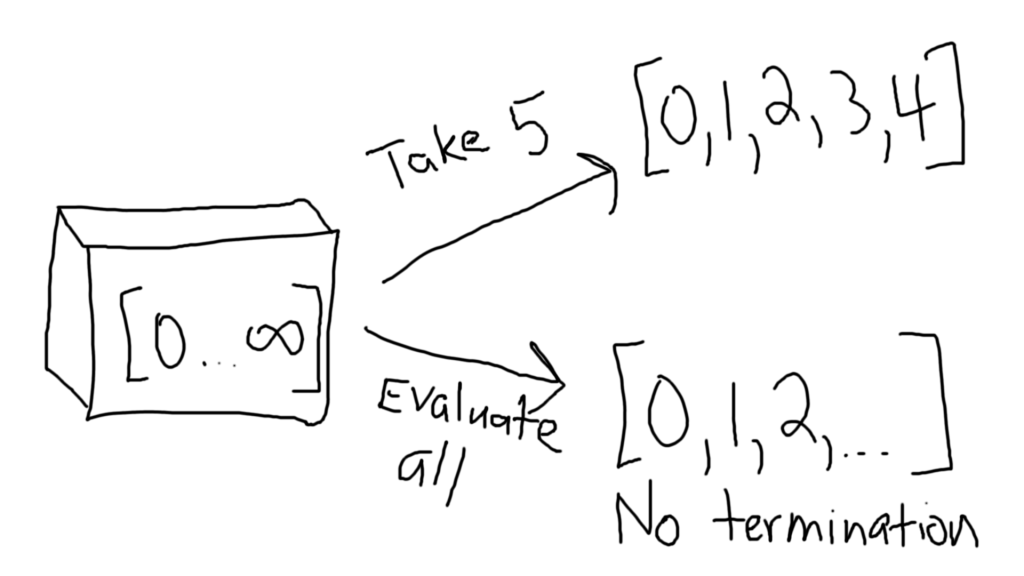
There is no doubt that this expression is infinite and contains all of the numbers from 0 to infinity. And yet, it doesn’t take up infinite memory, despite having an infinite size.
We can even take the first 5 terms out of this infinite list, and not crash. Why’s that? It’s because when you want to take the first 5 terms out, you evaluate only the first 5 terms in the list. As far as you are concerned, the other terms simply don’t exist, because you didn’t evaluate them into existence.
This means that you can pull finite results out of infinite lists, while also taking finite time and finite space. Note, however, that if you attempt to evaluate the entire list, it will end up taking infinite time, because each value of the list will materialize as each of the subexpressions get evaluated.
Consequently, if you tried to do anything like getting the length of the list, or trying to retrieve the last element in the list, you would not get a terminating result, because both of those require finding a final element, which doesn’t exist in the infinite list, and would require infinite evaluations to occur.
That sounds nifty and cool, but what about real-world applications?
If you’ve ever used a stream in any language (eg; Java streams), then you’ve used lazy evaluation. Streams, by nature, can be optimized by taking advantage of lazy evaluation.
In a real-world environment, streams can have millions to billions of elements. What if you wanted to concatenate two streams that each had at least 1 billion elements? Clearly, you can’t load either of the streams into memory, because that would quickly exceed memory limits.
This means you need to process the streams as abstract expressions, rather than as concrete values. Think of the streams as being two boxes, each containing potentially infinitely many items. With lazy evaluation, concatenating them together is a piece of cake — just put the two boxes inside of a new box.

At no point did you care about the insides of the stream, nor did you ever have to open the streams. This process has constant space and time complexity
With a non-lazy approach, you’d have to pull everything out of the second stream, find the ending element of the first stream, and then append each of the stream’s second elements one by one. Furthermore, you have to assume that no one adds any new elements into stream 1 as you’re appending the items in stream 2, which is a very big assumption to make. The reason the lazy approach doesn’t have this problem, is because you’re literally just stuffing the two streams into a new stream, without needing to know how many elements are in each of the streams, or what the elements are.
Conclusion
So with that, I hope you’ve gotten a better understanding of how lazy evaluation works. It has plenty of real-world use cases, and generally allows you to do operations on two, potentially infinite things, in constant time.
Lazy evaluation also allows you to defer errors until the very last moment, in which you have to evaluate an erroneous expression, at which point everything blows up. But if the erroneous expression is never needed (and thus never evaluated), then the error may as well not exist, which can be quite useful in some project workflows.
As a final note, lazy evaluation has some very notable drawbacks that you will need to be aware of. Firstly, if what you are doing is time-sensitive, like reading the current time, you will to immediately evaluate it on the spot.
This is because the “time” that you have is actually an expression that fetches the current time. The “current time” will actually be the time at which you evaluate it, and not the time at which the expression was created.
If you tried to time how long a program took to run by lazily fetching the start time, running the program, then lazily fetching the end time, you would find that both your start and end time are the same, and so it would output that the program took 0 seconds to run!
Hopefully, you’ve learned a bit about lazy evaluation from this article. There’s plenty more to learn about lazy evaluation, but the gist of it is that you can’t always use lazy evaluation.
As they old adage goes, sometimes, it pays to be lazy.
