Have you ever had a child ask you, “Why is the sky blue?”
If so, how would you respond? Would you say, “Well, you see, there are lots of tiny molecules in the atmosphere, and thanks to a phenomenon called Rayleigh scattering, blue light gets scattered more strongly than the other colors because blue light has a longer wavelength than the other colors.”
While this answer is correct and thorough, no child would understand this.
But instead, what happens when you explain it by showing a child a triangular prism with sunlight reflecting through it?

Visible light goes in, a spectrum of colors comes out. And just like how this prism can scatter light into different colors, the same thing happens in the sky, except it reflects off mostly blue instead.
How do you feel about this answer? From a technical aspect, it’s very hand-wavy and magical. There’s no explanation about why the scattering happens, or why visible light can even split into individual colors. But oddly enough, when you give this explanation to a child, they suddenly just understand it intuitively, so intuitively in fact that they’ll even be able to explain why a puddle can form a tiny little rainbow.
But we didn’t mention anything about puddles. Or the fact that visible light is a spectrum of wavelengths, with several bands that correspond to different colors. And yet the intuition and understanding is there. Isn’t that odd?
How Most Programmers Learn
It turns out that this principle applies to programmers as well. In my experience, after teaching programming for several years, many programmers fall into this pitfall because they “need to understand how everything works”.
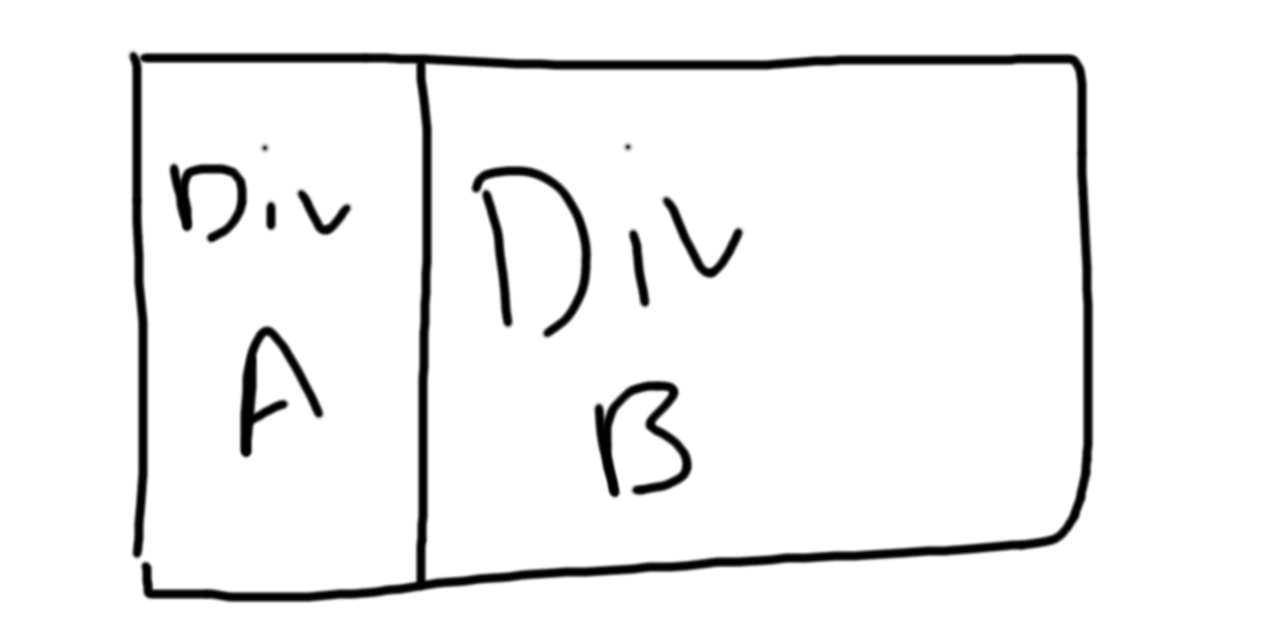
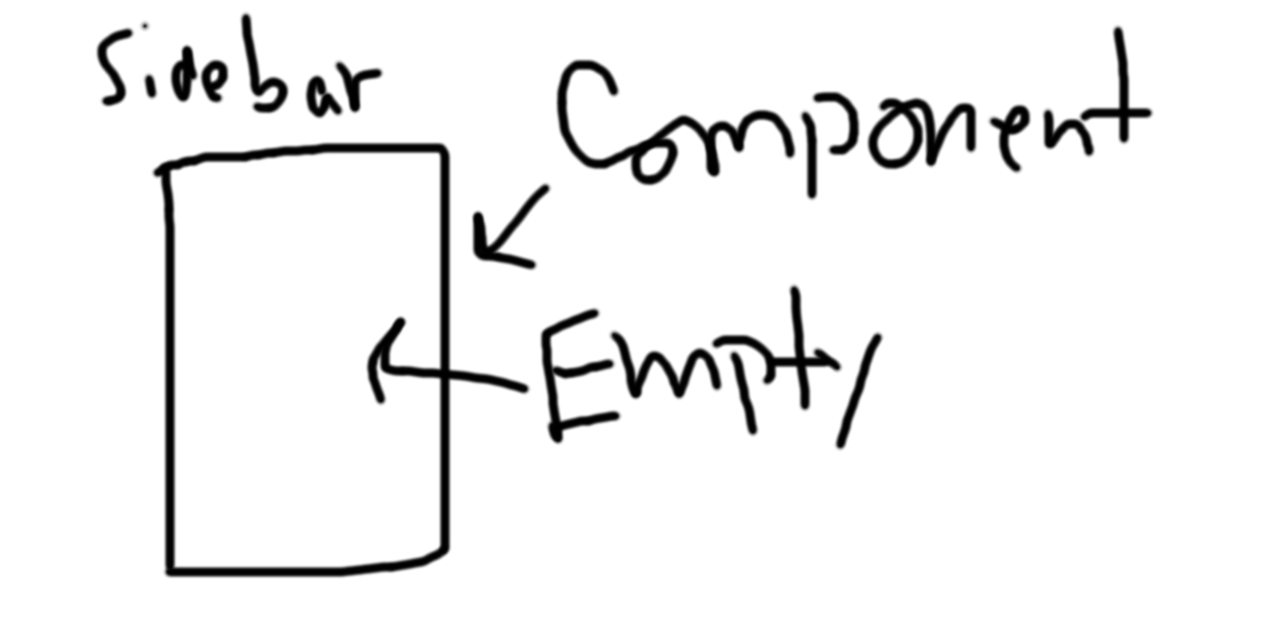
Let’s start with a simple example. You need to use Docker because you want to setup a scalable microservice configuration. To quickly summarize this for anyone unfamiliar with Docker, you’ll use Docker to put a tiny, individual piece of an app, like a login system, into a “container”. Then you can create many copies of those containers, which in turn allows you to handle a ton of logins at once.
Based on my own personal experiences, this is how most programmers would learn Docker.
First, they would open up Docker’s getting started page. After that, they would spend five minutes looking at the page before realizing that they don’t understand what a container is.
At this point, you might think, “If I don’t understand what a container is, then I can’t understand anything else on this page! I need to Google with a container is.”
So they go on to research about containers, and every post about containers on Docker’s documentation is going to talk about containers v.s. virtual machines. Eventually, they’ll bump into this diagram:

Image from Docker’s official documentation
And you might think, “Oh no! I don’t know how hypervisors work!”, which then leads you to spend another hour researching hypervisors.
By the time you finally understand what containers do, and how they work, you’ve already wasted several hours of research. Unfortunately, learning about this was only one piece of the puzzle. You still can’t Dockerize your app, and so you’ve actually made zero progress towards your goal of creating a scalable microservice setup.
A More Effective Way of Learning
The reason why the previous approach doesn’t work is because it causes you to care about too many details. When learning something new, it’s important to remember why you’re learning it. Are you learning it to do a particular goal? If so, then you only need just enough details to solve the task, and no more.
In the example I gave before with the “Why is the sky blue” question, it’s enough for you to know that things can refract light into individual colors. Knowing this fact gives you enough information to deduce that the sky, or something in the sky is refracting the light into blue light. You don’t need to know about the details of Rayleigh scattering, or the physics behind how the wavelength of a photon is affected when it collides into a molecule.
Similarly, you have to remember that your goal isn’t to “learn” Docker, but rather to use it to solve a particular problem. In this case, it’s enough to understand the very bare basics.
So how do you figure out what the bare basics are? It’s easy. You look at an example Docker setup. There are some really simple Docker setups, like the “Hello World!” Docker image. Once you’ve looked at one or two setups, it should be apparent that the bare necessities for a non-trivial app are:
- A Dockerfile
- Some source files that your Dockerfile will read from
In a nutshell, if this is how you learned Docker, your entire understanding of Docker boils down to this:

Without understanding any of Docker’s underlying workings, you should now be able to create simple Docker images without fail. Will you be able to do Docker images with volumes for storage persistence, intermediate layers, and complex networking? No, probably not. But the more important question is whether you had to learn all of those things before making your first Docker image.
From my experience with teaching programming to younger students (elementary school to high school students), I’ve realized that the fastest way to learn something is to just directly do it, and learn whatever you need on the spot. Any information that you don’t currently need is simply ignored until necessary.
For example, even though the shabby diagram above doesn’t include anything about networking or persistence, it’s trivial to just find an example of networking with Docker, and applying it to your setup. In fact, even when it comes to images and containers, there’s no understanding outside of “Here is an image. It creates a container”, because you don’t need it!
Suppose that in the future, you have a new requirement, which is that your image sizes need to be tinier. Then, and only then, should you decide to figure out how images actually work. If image size and performance is not a concern, then there is no reason for you to learn about how images work.
So You’re Saying Learning Is Bad?
At this point, you’re probably thinking that this ideology is insane, and that no one should learn things so haphazardly. Ignoring as many details as possible may seem jarring to many people, but to me, this is a matter of intuition versus understanding.
While it’s true that you’re more likely to run into unexpected problems by learning in such a hand-wavy way, learning this way minimizes the risk that you produce no output at all. Often times, when writing software, the problem at hand is this: Do you have a solution? Or do you not have a solution? Very rarely is it, “Is this solution fast/robust/flexible enough?”, because solutions can always be iterated upon, but you can’t iterate on a solution if you have no solution.
Returning back to the issue with Docker, you can understand everything there is to understand about Docker, you can list all of the intricacies that power it, and explain all of the “magic” behind Docker, but if you can’t create a Dockerized app, then you don’t intuitively understand Docker. If you were tasked tomorrow with creating a Docker image, and you couldn’t do it, then that should be an immediate red flag that you don’t actually understand Docker.

Reading is not a substitute for doing.
Just like how a blind physicist can know everything everything there is to know about the color red, like its wavelength, and how the optical cones in your eye can detect red, a blind physicist will still never intuitively know what “red” is, unless he or she sees it. Non-blind people who have seen the color red already know everything that they need in order to intuitively understand what “red” is, even if they don’t know the physics behind it.
Similarly, you can know everything there is to know about Docker, but if you’ve never used Docker to create containers, then you’ll never build your intuition for what Docker is, and how it feels to use Docker.
However, unlike the blind physicist, it’s entirely possible for you to learn everything there is to know about Docker, and then use Docker. But from my experience, doing it in this order is incredibly inefficient because you often times learn grossly more than needed.
If you’re still not fully convinced, consider this question:
Is it possible for a person to learn how to ride a bike solely by reading about how to do it? And if so, would your skill in riding a bike be better after 10 hours of reading about bike riding, or 10 hours of physically riding a bike?