Imagine that you’re a software developer for a company that monitors nuclear reactors.
On average, every 1 hour, a warning gets triggered at any individual nuclear reactor. Since these warnings could lead to something catastrophic, they must be monitored in real-time, as every second counts.

Assuming you have one million clients, all of whom need to be notified, what’s an efficient way to do so, while also minimizing server load?

The Naive (And Terrible) Solution
The most straightforward way to solve this problem is to create an API that allows any client to ping your servers to figure out if any warnings have triggered.
At first glance, this looks like a good idea, since writing a RESTful endpoint like this isn’t particularly hard.

However, there’s a problem here. You know that on average, a warning only triggers every 1 hour.
You also know that the client is heavily concerned about these warnings, and since the client needs the warnings in “real-time”, let’s just conservatively assume that the client checks every 1 second for a warning.
| Average number of warnings per hour | Number of times a client checked per hour | Average number of checks with no results (no warning found) |
| 1 | 3600 | 3559 |
| 60 | 3600 | 3540 |
| 1200 | 3600 | 2400 |
| 3600 | 3600 | 0 |
In the table above, you can see that there’s clearly a problem here. Regardless of the number of average warnings per hour, the client is still checking 3600 times an hour. In other words, as the average number of warnings goes down, the number of pointless checks goes up.
At 1 warning per hour, across 1 million clients, you would have over 3.5 billion unnecessary checks per hour. Even if we disregard how horribly inefficient this is, the real question is whether your servers can even comfortably handle that load without crashing.

Clearly, we can’t allow the client to grab the data on their own every 1 second, because this would cause a horrifically large amount of traffic (over 3.5 billion requests). Remember, at an average of 1 warning per hour, across 1 million clients, we should only have to send, on average, 1 million responses.
Sounds like a tough problem, but that’s where webhooks come in!
Introducing: Webhooks!
Webhooks are like reverse APIs. They’re like interviewers saying “Don’t call us, we’ll call you”.
Instead of having your clients ping your API every 1 second, you simply ping the client whenever a trigger occurs. Since you are only notifying the client whenever a warning occurs, it means that the client only gets notified when a warning exists. Therefore, there is no unnecessary traffic. You send out exactly 1 million responses, one per warning, and it’s still done in real-time.
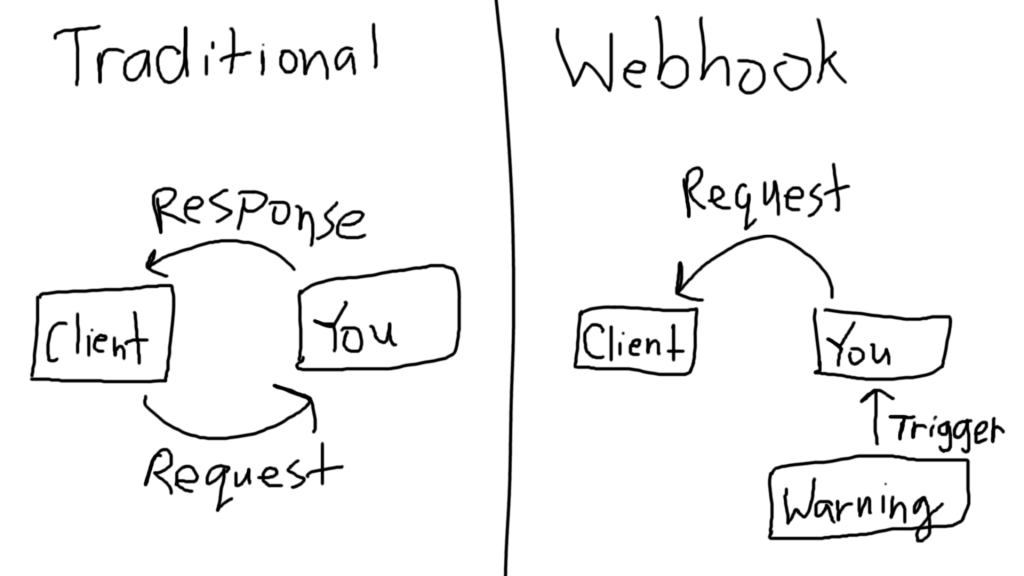
But how does the client “receive” the request?
Remember how I said a webhook is like a reverse API? The client is the one who writes the RESTful endpoint. All we have to do is record the URL to the endpoint, and each time the warning triggers, we send an HTTP request to the client (not expecting a response, of course).

What the client does with your POST’d request doesn’t matter. The client, in fact, can do anything they want, as long as their endpoint is registered with you.
This process can be generically applied to an infinite number of clients, by linking each client to the endpoint that they provided.
To summarize,
- Clients need to create a RESTful endpoint.
- Client gives you the URL to the endpoint.
- You save the endpoint somewhere.
- Anytime a warning triggers for that particular client, you send a POST request, with the warning enclosed, to the endpoint that they gave you.
- Client receives the POST request automatically, in real-time, and handles the warning in whatever fashion they want.
Conclusion
A webhook is an incredibly useful and simple tool that allows you to send data to clients in real-time based on some event trigger. Since the data is sent immediately after the event trigger, webhooks are one of many effective solutions for real-time event notification.
Additionally, since webhooks work in a “don’t call us, we’ll call you” fashion, you will never have to send a request unless an event trigger happens, which results in much lower server traffic.
In the example given above, at 1 warning per hour, across 1 million clients, using webhooks reduces the number of API calls from over 3.5 billion per hour to exactly 1 million per hour.
So the next time you have a situation where you need to notify clients based on some sort of event trigger, just remember this simple motto — “Don’t call us, we’ll call you”.